这两年python特别火,火到博客园现在也是隔三差五的出现一些python的文章。各种开源软件、各种爬虫算法纷纷开路,作为互联网行业的IT狗自然看的我也是心痒痒,于是趁着这个雾霾横行的周末瞅了两眼,作为一名老司机觉得还是应该以练带学,1024在程序员界这么流行的网站,当然拿来先练一练。
python自称是以自然语言的视角来编程,特点是开发快,语言简洁,没那么多技巧,大名鼎鼎的豆瓣、youtube都是使用python开发的网站,看来python在大规模使用这个方面来讲应该没有啥子问题;python也不是没有缺点在性能方面就Java、C++等老前辈还是没得比的,另外python和nodejs一样只能使用CPU单核,也是性能方面影响是因素之一。但python在特定领域表现突出,特别是脚本、爬虫、科学算法等。
好了,还是说正事如何爬取1024网站的图片
分析
列表页面
首先进入1024的导航网站,随便点击一个地址进入选择图片区或者在网站地址后面添加thread0806.php?fid=16&search=&page=,这就是1024网站的图片区,这个爬虫就是主要抓取这个区域的所有图片,使用浏览器debug分析一下这个页面发现基本都是列表页,格式如下:
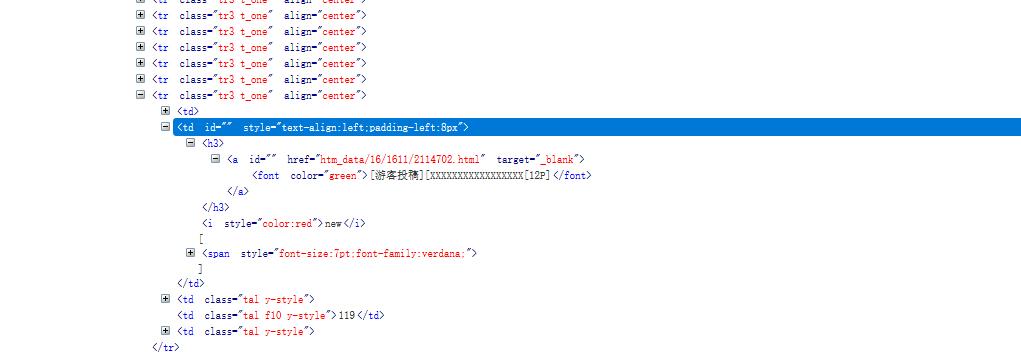
在地址栏http://xxxxxx.biz/thread0806.php?fid=16&search=&page=后面拼1、2、3等于就是访问图片区第一页、第二页、第三页的列表页。根据这些列表页就可以爬出具体的每一个图片页的地址,类似上图的地址:htm_data/16/1611/2114702.html 在地址的前面拼接上主站地址就是具体的图片页了。所以根据以上的分析:通过循环地址栏找到不同的列表页在根据列表页找到具体的图片页
地址栏->图片列表->图片页地址
获取列表页图片地址代码如下:
import urllib.request,socket,re,sys,os
baseUrl='http://xxxx.biz/'
def getContant(Weburl):
Webheader= {'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.103 Safari/537.36',}
req = urllib.request.Request(url = Weburl,headers=Webheader)
respose = urllib.request.urlopen(req)
_contant = respose.read()
respose.close()
return str(_contant)
def getUrl(URL):
pageIndex = 1
for i in range(1,int(pageIndex)+1):
Weburl = URL + str(i)
contant = getContant(Weburl)
comp = re.compile(r'<a href="htm_data.{0,30}html" target="_blank" id=""><font color=g')
urlList1 = comp.findall(contant)
comp = re.compile(r'a href="(.*?)"')
urlList2 = comp.findall(str(urlList1))
urlList = []
for url1 in urlList2:
url2 = baseUrl+url1
urlList.append(url2)
return urlList
URL = baseUrl+'thread0806.php?fid=16&search=&page='
UrlList = getUrl(URL)
print(UrlList)
在这个地址后面拼接1到N就是不同的列表页
图片页面
利用浏览器debug一下页面,图片基本上都是外链地址,以http或者https开头以jpg、png、gif结尾,写个正则表达式匹配这些地址,然后交给程序下载就OK了。
页面代码如下:
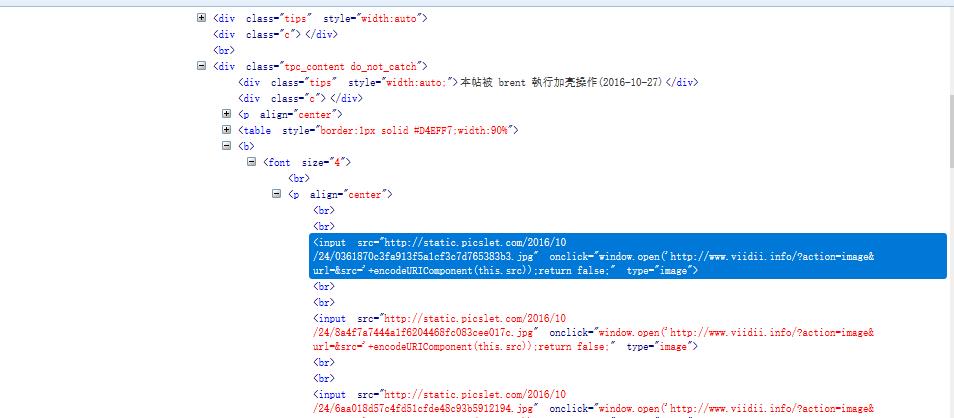
在下载过程中遇到了几个问题,就是有的页面会报403禁止访问等,应该是网站加了一些防止爬虫的手段,网上找了下加上header参数来模拟浏览器访问就解决了;
下载单个页面代码如下:
import urllib.request,socket,re,sys,os
#定义文件保存路径
targetPath = "D:\\temp\\1024\\1"
def openUrl(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/51.0.2704.63 Safari/537.36'
}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
data = res.read()
downImg(data)
def downImg(data):
for link,t in set(re.findall(r'([http|https]:[^\s]*?(jpg|png|gif))', str(data))):
if link.startswith('s'):
link='http'+link
else:
link='htt'+link
print(link)
try:
opener=urllib.request.build_opener()
opener.addheaders=[('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1941.0 Safari/537.36')]
urllib.request.install_opener(opener)
urllib.request.urlretrieve(link,saveFile(link))
except:
print('失败')
def saveFile(path):
#检测当前路径的有效性
if not os.path.isdir(targetPath):
os.mkdir(targetPath)
#设置每个图片的路径
pos = path.rindex('/')
t = os.path.join(targetPath,path[pos+1:])
return t
url = "http://xxxx.biz/htm_data/16/1611/2115193.html"
openUrl(url)
批量爬取
批量爬取有两个工作要做,第一for循环目标内的所有列表页,第二为了避免重复爬取,需要给每个页面建立唯一的文件夹,下次爬取的时候如果存在直接跳过。最后在理一下所有的爬取步骤:
循环地址栏->找出图片页列表->图片页分析找出图片地址->为图片页建立唯一的文件夹->开始下载页面图片
完整的代码如下:
import urllib.request,socket,re,sys,os
baseUrl='http://xxxx.biz/'
targetPath = "D:\\temp\\1024\\"
def getContant(Weburl):
Webheader= {'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.103 Safari/537.36',}
req = urllib.request.Request(url = Weburl,headers=Webheader)
respose = urllib.request.urlopen(req)
_contant = respose.read()
respose.close()
return str(_contant)
def getUrl(URL):
pageIndex = 1
for i in range(1,int(pageIndex)+1):
Weburl = URL + str(i)
contant = getContant(Weburl)
comp = re.compile(r'<a href="htm_data.{0,30}html" target="_blank" id=""><font color=g')
urlList1 = comp.findall(contant)
comp = re.compile(r'a href="(.*?)"')
urlList2 = comp.findall(str(urlList1))
urlList = []
for url1 in urlList2:
url2 = baseUrl+url1
urlList.append(url2)
return urlList
def openUrl(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/51.0.2704.63 Safari/537.36'
}
filePath=targetPath+url[-12:-5]
#检测当前路径的有效性
if not os.path.isdir(filePath):
os.mkdir(filePath)
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
data = res.read()
downImg(data,filePath)
else:
print("已经下载过的地址跳过:"+url)
print("filePath "+filePath)
def downImg(data,filePath):
for link,t in set(re.findall(r'([http|https]:[^\s]*?(jpg|png|gif))', str(data))):
if link.startswith('s'):
link='http'+link
else:
link='htt'+link
print(link)
try:
opener=urllib.request.build_opener()
opener.addheaders=[('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1941.0 Safari/537.36')]
urllib.request.install_opener(opener)
urllib.request.urlretrieve(link,saveFile(link,filePath))
except:
print('失败')
def saveFile(path,filePath):
#设置每个图片的路径
pos = path.rindex('/')
t = os.path.join(filePath,path[pos+1:])
return t
def openPage(UrlList):
for pageUlr in UrlList:
try:
print('正在下载地址:'+pageUlr)
openUrl(pageUlr)
except:
print('地址:'+pageUlr+'下载失败')
URL = baseUrl+'thread0806.php?fid=16&search=&page='
for num in range(0,20):#0-20页
print("#######################################")
print("##########总目录下载地址###############")
print(URL+str(num))
print("#######################################")
print("#######################################")
UrlList = getUrl(URL+str(num))
openPage(UrlList)
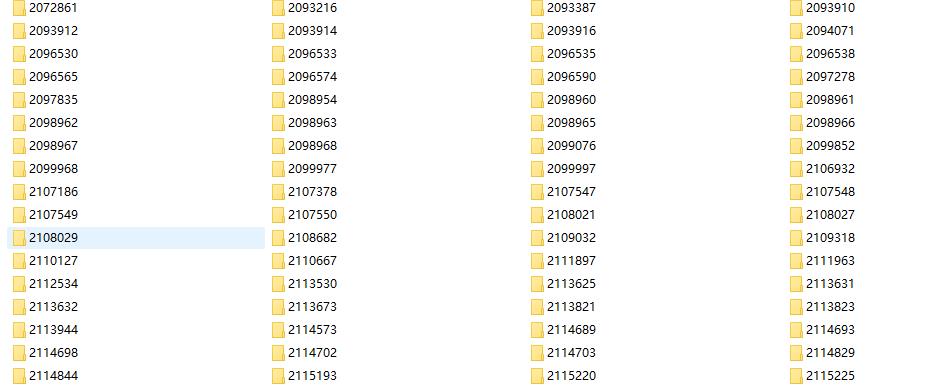
最后的爬取结果:
源代码地址:python-crawler
具体地址和源代码在一起
其它
关于python2和python3的争论,网站争论比较大python3不兼容pyhton2,很多第三方的类库暂时还没有支持python3等等,但是对于我们新手来说,肯定是往前看果断python3.
代码比较冗余几个地方还没有写好,还在慢慢学习中,目前只是搞的可以跑起来。还有几个问题没有解决,下载一段时间后会莫名其妙的断掉目前还么找到原因,后期看是否可以加上多线程来爬取可能会快一点,大家有什么更好的建议也可以提出来。
参考:
作者:纯洁的微笑
出处:www.ityouknow.com
版权所有,欢迎保留原文链接进行转载:)

Post Directory
